
In our “Engineering Energizers” Q&A series, we shine a spotlight on the innovative engineering minds at Salesforce. Today, we feature Gloria Yu, a Director of Software Engineering who leads the Ingress Gateway team. This globally distributed platform ensures secure, high-performance access to the Hyperforce environment.
Discover how Gloria’s team successfully navigated a sudden 5x traffic surge, addressed autoscaling challenges, accelerated deployments while maintaining trust, and scaled the system to manage unpredictable global traffic, supporting over 100 billion daily requests across more than 25 AWS regions.
What is your team’s mission?
The team builds and operates one of the most critical systems in Salesforce’s public cloud stack. As the gateway to Hyperforce, Ingress Gateway manages nearly all external traffic, including logins, browser sessions, APIs, and cross network boundary service-to-service communication, ensuring secure, efficient, and low-latency routing.
But this is more than just infrastructure maintenance. The team actively develops and scales a platform that operates as a Tier 0 service, engineered for 99.99% uptime and designed to handle unpredictable global traffic patterns. Every enhancement — whether it’s smarter routing logic, tighter certificate renewal workflows, or deeper observability — is meticulously built, tested, and deployed across a vast footprint:
- 25+ AWS regions
- 850 internal services supported
- 23,000 virtual IPs managed
- 1,400+ independently managed deployments across Hyperforce
Built on top of Envoy and Istio, the platform is fully programmable and policy-driven. This gives the team the flexibility to ship changes quickly while maintaining standardized ingress behavior across environments. Whether onboarding new services, simulating failure conditions, or redesigning autoscaling policies, the team sees Ingress as a living system—constantly evolving to meet the growing demands of the business.
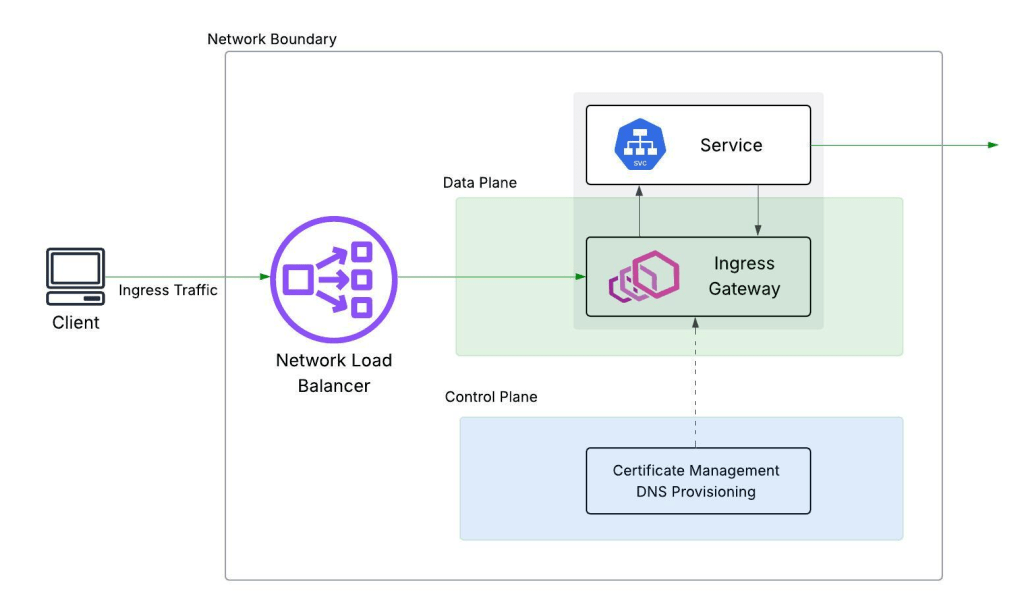
A high-level look at Ingress Gateway’s architecture.
What was the most significant technical challenge that your team faced as it relates to Ingress Gateway?
One of the most significant challenges occurred last year. Over a single weekend, a substantial number of tenants transitioned from first-party infrastructure to Hyperforce. By Monday morning, traffic to Ingress Gateway spiked by 500%, far beyond the anticipated load.
Despite having autoscaling enabled, the system struggled to keep up. The platform was optimized for CPU utilization, but the new tenants generated memory-intensive traffic, causing the horizontal pod autoscaling to respond too slowly. Circuit breakers activated to contain the impact, which protected the broader platform but led to degraded performance for the affected tenants. This highlighted critical gaps in the autoscaling strategy.
As a secondary action item, the team overhauled the test and simulation infrastructure to more accurately reflect production behavior. Load tests were updated to include both CPU and memory profiles, and deeper telemetry was implemented to enhance visibility into scaling triggers and circuit breaker events. The goal: prevent future traffic spikes from causing similar disruptions.
How do you manage challenges related to scalability in Ingress Gateway?
Scalability is an ongoing engineering challenge. Ingress Gateway must handle unpredictable surges, regional spikes, and long-tail behaviors from thousands of organizations, so the team avoids assuming static traffic patterns.
To prepare, engineers invest heavily in pre-production simulations. Custom workloads mimic real-world production behavior, considering factors like concurrency, routing depth, and request size. These tests are based on real telemetry to accurately reflect live usage.
The team also participates in company-wide chaos engineering exercises, simulating failures such as Availability Zone (AZ) outages, secret unavailability, and traffic shifts. Engineers monitor system behavior, detect anomalies, and document real-time recovery responses.
Today, Ingress Gateway processes approximately 100 billion requests per day, supported 24/7 by a globally distributed team of 20 engineers across the U.S., Ireland, and India.
How do you balance the need for Ingress Gateway’s rapid deployment with maintaining high standards of trust and security?
Deploying quickly doesn’t mean sacrificing safety. Every change to Ingress Gateway goes through Managed Releases, a company-wide system that ensures changes are thoroughly tested before going live.
Each change starts in a test environment and stays there for a set soak period. This allows issues to surface in a low-risk environment early in the development cycle. Only after a change proves stable can it be promoted to additional environments used for certification and staging before finally reaching production.
The team also runs custom integration tests specific to Ingress Gateway. These tests check critical functions like TLS handling, domain resolution, routing logic, and upstream connectivity. They run in every deployment pipeline and act as an early warning system for subtle issues.
If a problem is detected—whether through automated tests, telemetry during the soak period, or manual review — rollbacks can be initiated without impacting the entire global footprint. This lets engineers deploy critical fixes quickly while maintaining the stability needed for a Tier 0 service.
What strategies did your team employ to ensure that enhancements in one area of Ingress Gateway didn’t compromise others?
Preventing regressions is crucial. Even minor changes are treated as potential risks because Ingress Gateway is a shared foundation for hundreds of internal services that depend on predictable ingress behavior for CI/CD, testing, and production uptime.
To minimize impact, the team uses scoped deployments, rolling out changes one region or environment at a time with built-in soak periods. This staged approach helps catch unexpected issues early.
Functional Integration Tests (FITs) provide an additional layer of protection. Each scrum team writes and maintains its own test suite to validate critical behaviors like cert renewal, routing logic, and load balancing after deployment.
For cross-organizational enhancements, the team collaborates with other engineering groups. They stage changes, monitor shared metrics, and perform manual QA when necessary to avoid unintended downstream impact.
What ongoing research and development efforts are aimed at improving Ingress Gateway’s capabilities?
R&D efforts are focused on enhancing availability, resource efficiency, and integration resilience. Current initiatives include:
- Adaptive Concurrency: Improving how traffic limits are managed during upstream failures with smarter circuit breaker logic that adapts to detailed resource patterns.
- Advanced Certificate Management Automation: Enhancing renewal cycles and alerting systems to reduce downstream risk. Test automation ensures certificate workflows are validated in pre-production. Since Hyperforce’s launch, automated renewal has managed tens of thousands of certificates with virtually no issues. The team currently handles 7,000–10,000 certs for the Salesforce core application, all renewed and applied automatically without any customer downtime.
- Dependency Optimization: Addressing performance bottlenecks by prototyping changes to reduce latency and improve fault tolerance during certificate provisioning and peak load.
- Traffic Sharding: Grouping organizations more efficiently to reduce idle overhead and improve cost-to-serve across the global fleet, rather than scaling through more deployments.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.



